Dados Tabulares:
A Maneira Pythônica
Turicas aka Álvaro Justen
VIII Encontro PythOnRio
30 de abril de 2016, Elo Group - Rio, Brasil
Turicas, prazer! =)
{twitter.com, github.com, youtube.com, slideshare.net}/turicas
alvarojusten@gmail.com
turicas.info
Quem sou eu?
- Não tenho graduação
- Não trabalho em empresa
Software Livre

Python
![]()
Arduino

CursoDeArduino.com.br
![]()


bit.ly/pyrio-rows
Captura + Normalização


CSV
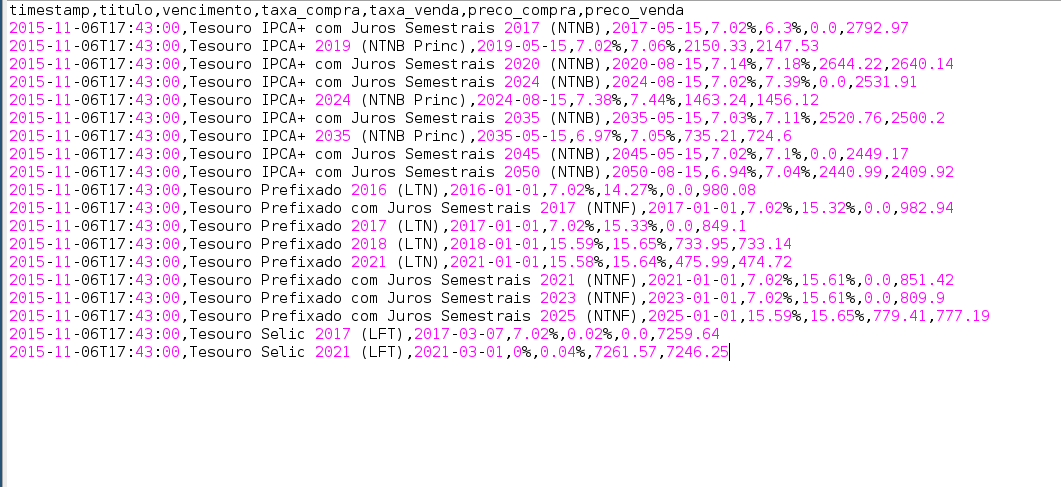
csv em Python
import csv
reader = csv.DictReader(open('tesouro-direto.csv'))
# TODO: identificar dialecto CSV
for row in reader:
print row # todo es string =/
# TODO: crear conversión de datetime
# TODO: crear conversión de date
# TODO: crear conversión decimal
# TODO: crear conversión percent
HTML
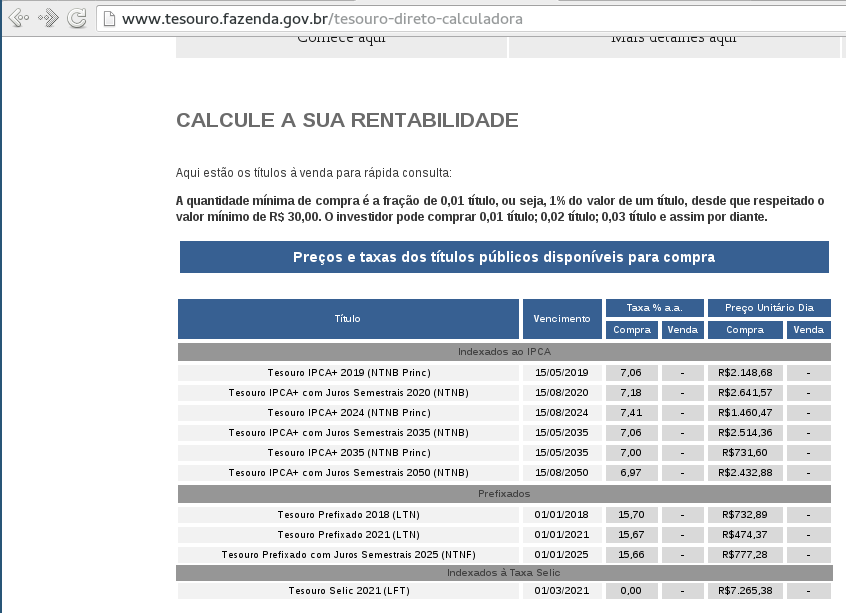
HTML
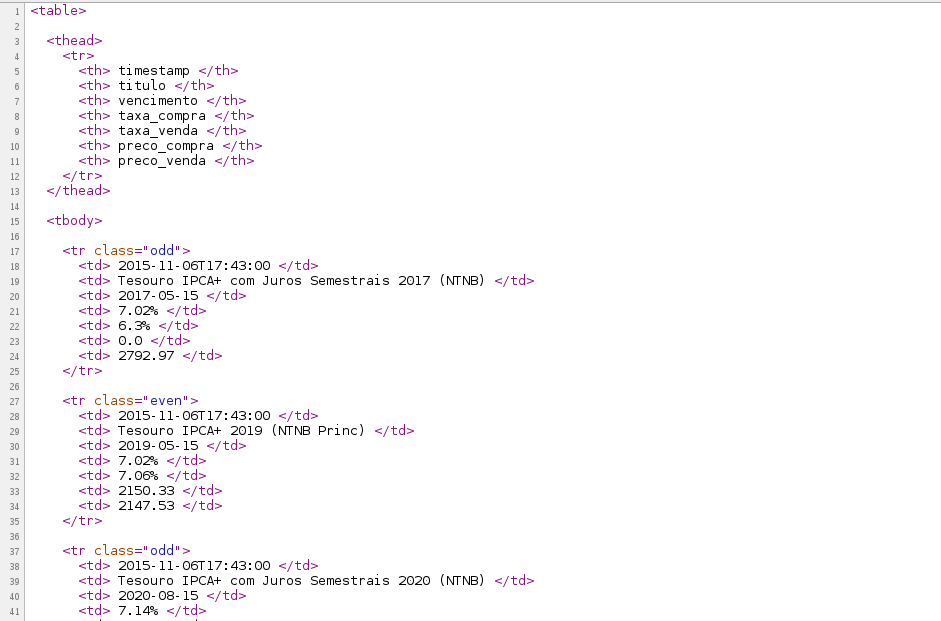
A vida não é tão fácil! :D

html em Python + lxml
pip install lxmlimport lxml.etree
filename = 'tesouro-direto.html'
html = open(filename).read()
tree = lxml.etree.fromstring(html)
table = tree.xpath('//table')[0]
# ... aburrido aburrido aburrido ...
# tentativa
# error
# tentativa
# error
# error
# error
...
:-/
XLS
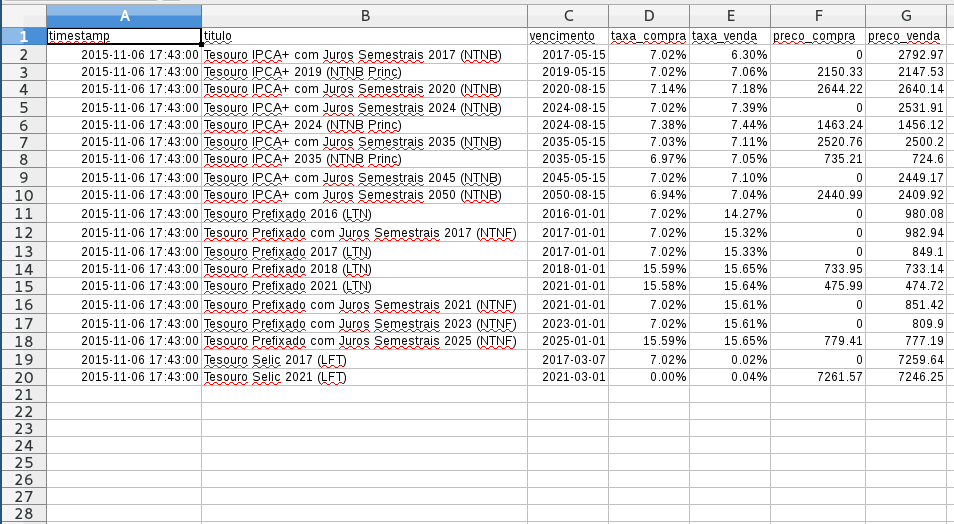
xls em Python + xlrd
pip install xlrdimport xlrd
filename = 'tesouro-direto.xls'
book = xlrd.open_workbook(filename, formatting_info=True)
sheet = book.sheet_by_index(0)
NUMERO_DE_COLUNAS = 7 # WTF?
header = [sheet.cell(0, col).value for col in range(NUMERO_DE_COLUNAS)]
NUMERO_DE_LINEAS = 19 # WTF?
data = [[sheet.cell(row, col).value for col in range(NUMERO_DE_COLUNAS)]
for row in range(1, NUMERO_DE_LINEAS + 1)]
for row_data in data:
row = dict(zip(header, row_data))
print row
# TODO: crear conversión de date y datetime
# TODO: crear conversión de decimal
# TODO: crear conversión de percent
Resultado...
{u'preco_compra': 0.0, u'timestamp': 42314.73819444444, u'vencimento': 42801.0, u'taxa_venda': 0.0002, u'taxa_compra': 0.0702, u'preco_venda': 7259.64, u'titulo': u'Tesouro Selic 2017 (LFT)'}..., u'timestamp': 42314.73819444444, ...rows to the rescue!
pip install rows # Python Package Index
apt-get install rows # Debian!
dnf install rows # Fedora
github.com/turicas/rows

csv com Python + rows
import rows
table1 = rows.import_from_csv('tesouro-direto.csv')
for row in table1:
print row
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ com Juros Semestrais 2017 (NTNB)', vencimento=datetime.date(2017, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.063'), preco_compra=0.0, preco_venda=2792.97)
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ 2019 (NTNB Princ)', vencimento=datetime.date(2019, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.0706'), preco_compra=2150.33, preco_venda=2147.53)
...xls com Python + rows
import rows
table2 = rows.import_from_xls('tesouro-direto.xls')
for row in table2:
print row
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ com Juros Semestrais 2017 (NTNB)', vencimento=datetime.date(2017, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.063'), preco_compra=0.0, preco_venda=2792.97)
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ 2019 (NTNB Princ)', vencimento=datetime.date(2019, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.0706'), preco_compra=2150.33, preco_venda=2147.53)
...html com Python + rows
import rows
table3 = rows.import_from_html('tesouro-direto.html')
for row in table3:
print row
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ com Juros Semestrais 2017 (NTNB)', vencimento=datetime.date(2017, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.063'), preco_compra=0.0, preco_venda=2792.97)
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43), titulo=u'Tesouro IPCA+ 2019 (NTNB Princ)', vencimento=datetime.date(2019, 5, 15), taxa_compra=Decimal('0.0702'), taxa_venda=Decimal('0.0706'), preco_compra=2150.33, preco_venda=2147.53)
...assert list(table1) == list(table2) == list(table3)print table1[0]
Row(timestamp=datetime.datetime(2015, 11, 6, 17, 43),
titulo=u'Tesouro IPCA+ com Juros Semestrais 2017 (NTNB)',
vencimento=datetime.date(2017, 5, 15),
taxa_compra=Decimal('0.0702'),
taxa_venda=Decimal('0.063'),
preco_compra=0.0,
preco_venda=2792.97)
# namedtuple #FTW \o/


pythonnordeste.org
9 a 11 de junho
Teresina/PI

fisl.org.br
13 a 16 de julho
Porto Alegre/RS ![]()

pythonsudeste.org
2 e 3 de setembro
Belo Horizonte/MG ![]()

pythonbrasil.org.br
13 a 18 de outubro
Florianópolis/SC